For three years the AI story has been the same: scale text, get smarter models. We are now hitting the natural ceiling of that bet. Language models are amazing reasoners on text, but they have no idea what a room looks like, how a door opens, or what happens when you push a coffee cup over the edge of a table.
The frontier moves next, and it has a name: spatial intelligence.
Fei-Fei Li, the Stanford researcher who built ImageNet and arguably kicked off the deep-learning era, summed up the bet in her TED talk:
In the beginning of the universe, all was darkness, until the first organisms developed sight, which ushered in an explosion of life, learning and progress.
Her argument: machines are about to undergo the same transition. Vision plus a 3D model of the world plus the ability to act in it is the next platform shift. Her company, World Labs, is built explicitly around that thesis.
This post is about what spatial intelligence actually is, what the four building blocks are, who is building each one in 2026, and why it matters for engineers, founders, and business owners outside the AI bubble.
What is spatial intelligence?
The cleanest definition comes from World Labs itself:
Spatial intelligence transforms seeing into doing, understanding into reasoning, and imagining into creating.
It is the ability for a system to perceive a 3D environment, reason about what is happening in it, generate new spatial possibilities, and interact with the world through tools, robots, or interfaces. Four moves. They map cleanly onto the same four pillars the AI research community is already organizing around:
- Understanding — seeing structures, patterns, relationships
- Reasoning — mentally manipulating, predicting outcomes
- Generation — creating new spaces, designs, futures
- Interaction — navigating, using tools, collaborating in physical or virtual environments
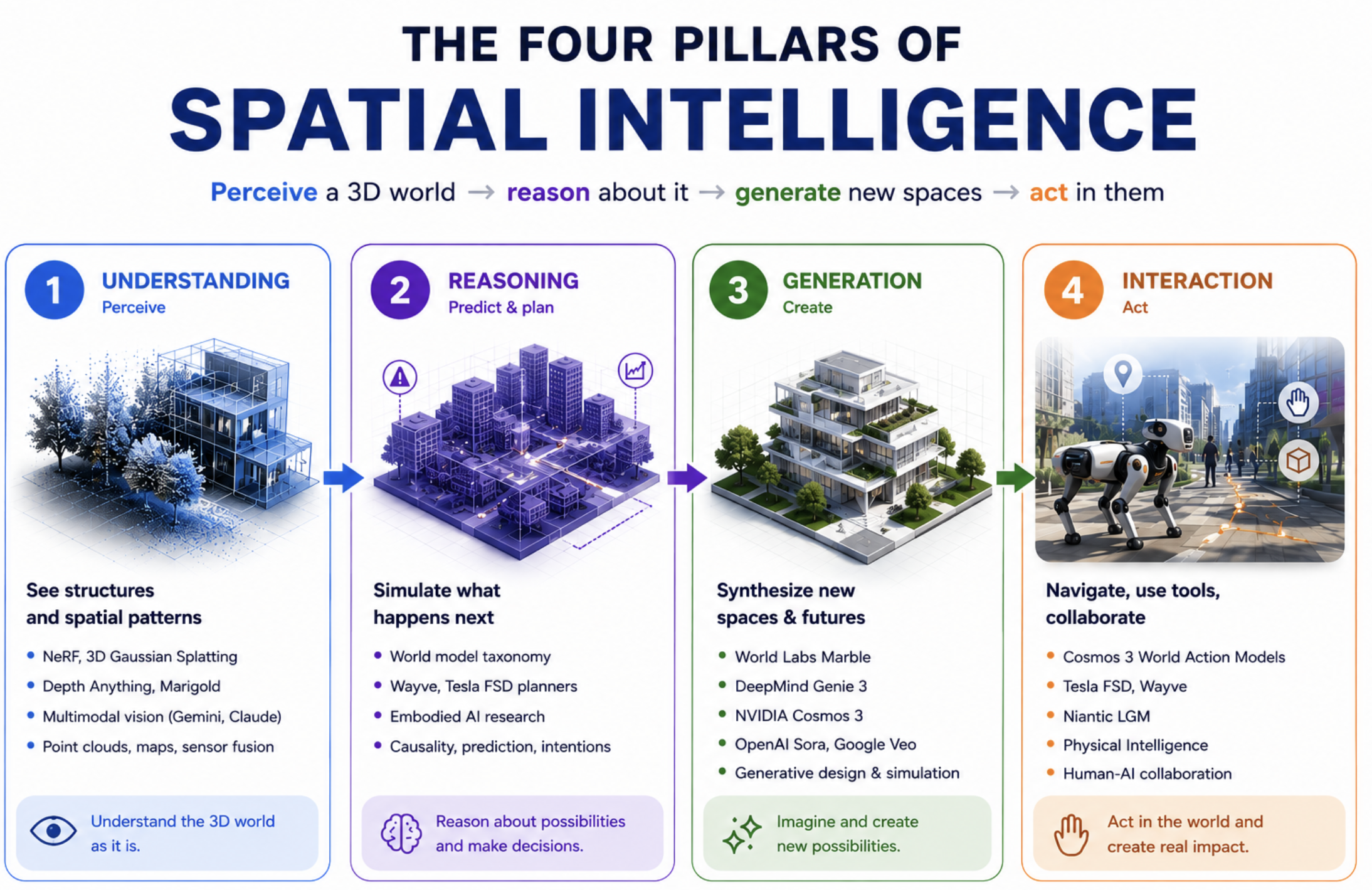
The four pillars of spatial intelligence and the systems shipping against each one.
The thing to notice is that LLMs only really do part of #2 well, and only in text. Everything else is the new frontier.
Why text wasn't enough
Large language models compress the internet into a flat probabilistic map of words. They are spectacular at reasoning over symbols, but they have no embodied understanding. Ask a GPT-style model to describe a room and it will produce a plausible sentence. Ask it which way the door swings, how far the desk is from the chair, or whether you can fit a sofa through a hallway, and the abstraction breaks.
This matters because the next big AI applications — robotics, autonomous vehicles, AR and VR, digital twins, simulation training, embodied agents — all require a system that understands and can predict what happens in 3D space. You cannot deploy a useful warehouse robot with a language model alone. You need a world model.
That is what spatial intelligence is meant to deliver. And in 2026, multiple labs are racing to deliver it.
The 4 pillars, with 2026 receipts
1. Understanding (perceive)
The reconstruction wave is here. Neural radiance fields (NeRF) and 3D Gaussian Splatting turned the field from "AI looks at images" to "AI builds a manipulable 3D scene from images." World Labs ships Spark, a framework for streaming Gaussian Splatting scenes on the web; Spark 2.0 dropped in April 2026 with Level-of-Detail systems for browser-grade fidelity. Depth foundation models (Depth Anything, Marigold) and multimodal models like Gemini and Claude's vision give systems the raw spatial substrate to work with.
2. Reasoning (predict, plan)
Most of the published research lives here, but the public demos are weakest. World Labs published A Functional Taxonomy of World Models in June 2026 splitting the field into three roles: renderers (what does the world look like?), simulators (what happens next?), and planners (what should I do?). The clearest production examples are in self-driving: Wayve's world models predict future video frames conditioned on driving actions; Tesla FSD's planner reasons over a learned 3D representation of the road.
3. Generation (create new spaces)
This pillar exploded between 2025 and 2026.
- World Labs Marble generates spatially consistent 3D worlds from text, images, video, or 360 panoramas. You can walk through them, edit them, expand them, and export them in multiple formats.
- Google DeepMind Genie 3 (August 2025) generates interactive 720p worlds at 24 fps from text, with several minutes of visual consistency and roughly a minute of visual memory.
- NVIDIA Cosmos 3 is the first "omni model" that does text, image, video, sound, and action generation in a single model. Earlier Cosmos versions kept perception and generation separate.
- OpenAI Sora and Google's Veo do video generation that requires implicit spatial coherence to look believable.
The race is about consistency. Genie 3 holds together for minutes; Marble lets you move through a world; Cosmos 3 ties generation to physics. Whoever wins the long-horizon consistency battle wins the foundation layer.
4. Interaction (act)
Generation without action is a demo. Cosmos 3 ships as the backbone for World Action Models, which are robotics policies trained against the simulated world. NVIDIA's pitch is straightforward: train robots in unlimited synthetic worlds, deploy them in the real one. Wayve and Tesla apply the same loop to driving. Niantic's Large Geospatial Model is a different angle: anchor AI in real geography so AR experiences stay in place across users and sessions.
The landscape at a glance

The 2026 landscape mapped against the four pillars. World Labs is the only player visible in all four columns.
| Pillar | Who's shipping in 2026 |
|---|---|
| Understanding | World Labs Spark, NeRF, 3D Gaussian Splatting, Depth Anything, multimodal LLMs (Gemini, Claude vision) |
| Reasoning | World Labs world model taxonomy, Wayve, Tesla FSD planners, embodied AI research at DeepMind and Meta |
| Generation | World Labs Marble, Google DeepMind Genie 3, NVIDIA Cosmos 3, OpenAI Sora, Google Veo |
| Interaction | NVIDIA Cosmos 3 World Action Models, Tesla FSD, Wayve, Niantic Large Geospatial Model, Physical Intelligence |
If you are mapping the field, World Labs is the only player touching all four pillars in one stack. NVIDIA is closest behind through Cosmos plus their robotics stack. Google DeepMind owns generation. The driving stacks (Tesla, Wayve) own reasoning plus interaction inside one vertical.
Why this matters for builders and business owners
The honest one-line answer: the next billion-dollar AI applications will be spatial, not textual. A few concrete bets:
- Robotics. Cosmos and Marble unlock simulation-trained robots that can be deployed in messy real warehouses. Half the productivity gains from AI in the next decade will probably run through robots, not chatbots.
- Autonomous vehicles. The fastest payback from spatial intelligence is already on the road. Wayve and Tesla are the proof.
- Digital twins. Industrial customers in manufacturing, oil and gas, and smart cities want spatially accurate, queryable models of their facilities. Marble plus Spark is a closer fit than anything in the LLM stack.
- AR and VR content. Generated worlds at minutes-long consistency turn AR from a demo to a platform. Apple Vision Pro and Meta's headsets need this layer to mean anything serious.
- E-commerce 3D. Try-before-you-buy at scale only works if you can synthesize 3D from a few photos. Spatial generation is the unlock.
- Climate and ecology. Earth observation already produces petabytes of spatial data. World models that can reason about it are the next leg of climate-tech AI.
The honest assessment
The frontier has limits. Consistency is still measured in minutes, not hours. Most of the impressive 2026 systems are research previews, not products you can integrate today. Compute cost is staggering: generating a single high-quality 3D world is closer to "minutes on a GPU cluster" than "real-time on a phone." Evaluation is open, with no spatial-intelligence benchmark anywhere near the maturity of MMLU for language.
These are the same kinds of gaps that LLMs had in 2020. Two things closed them: scale and tooling. Spatial intelligence is on the same trajectory, and the cycle is shorter because the spatial stack is being built by people who watched the LLM playbook in real time.
What to watch in the next 12 months
- World Labs releasing more of Marble's capabilities to wide access (the current version is gated)
- NVIDIA Cosmos 3's robotics demos converting into actual deployed robot fleets
- Genie 4 or whatever comes next, and whether Google can push consistency from minutes to hours
- The first spatial-intelligence benchmark that becomes a real leaderboard
- An open-weight world model that lets researchers and startups build on top of Marble, Cosmos, and Genie without paying for API access
Whoever owns the answer to "what does the world look like next?" probably owns the foundation layer for the next decade. The bet is on.
Dig deeper:
- World Labs — worldlabs.ai
- Fei-Fei Li TED talk — With Spatial Intelligence, AI Will Understand the Real World
- NVIDIA Cosmos — nvidia.com/en-us/ai/cosmos
- Google DeepMind Genie 3 — deepmind.google